
Has terminado de crear tu sitio web HTML y te sientes muy orgulloso del arduo trabajo. Pero hay una cosa que todavía falta: no tienes idea de cómo publicar tu sitio web.
En este paso a paso aprenderas como publicar un sitio web HTML utilizando dos plataformas populares: Netlify y GitHub.
Antes de iniciar asegurate de tener una cuenta de GitHub porque necesitaras alojar tu repositorio (código fuente).
Netlify es una plataforma para alojar sitios web. Es fácil alojar sitios en Netlify, ya que no necesita configurarlo manualmente. Si no se ha registrado para obtener una cuenta, ahora es un buen momento para hacerlo.
Este es el proceso paso a paso para publicar su sitio web en Netlify:
Agrega un sitio. Una vez que haya iniciado sesión, lo llevará a un panel de inicio. Haga clic en el botón Agregar nuevo sitio (Add new site) para agregar su nuevo sitio web a Netlify.
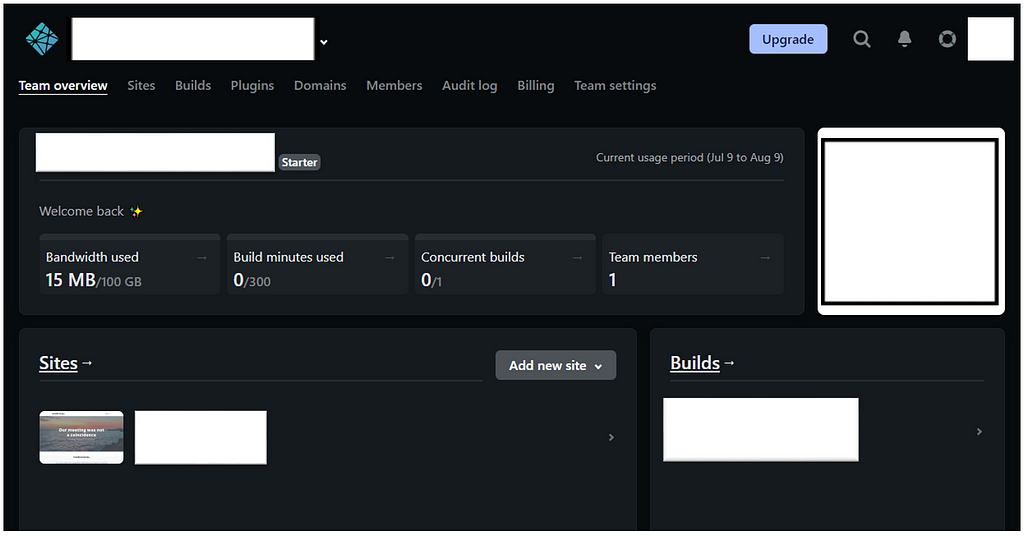
Importar tu repositorio de GitHub. Cuando haga clic en el botón Agregar nuevo sitio (Add new site), lo llevará a la página “Importar un proyecto existente”. Asegúrese de enviar su repositorio a GitHub para que Netlify pueda vincularse a su cuenta de GitHub.

Seleccionar el repositorio. Una vez que otorga permiso a Netlify, puede ver una lista de todos sus repositorios. Seleccione su sitio web para publicar.
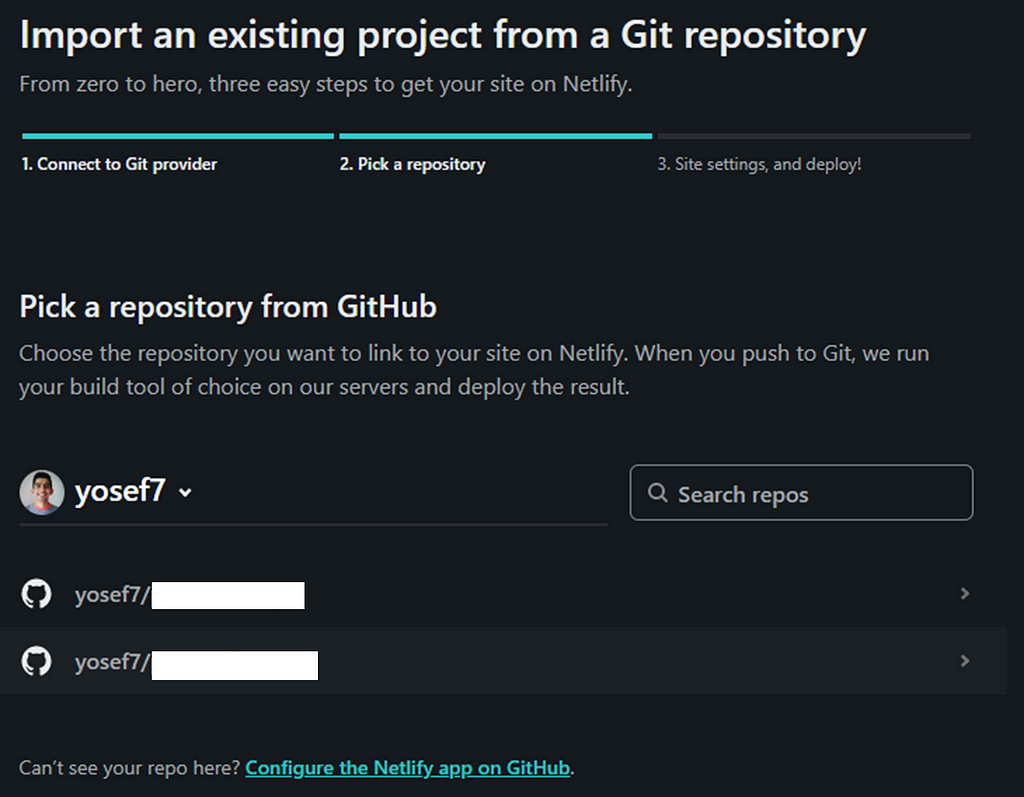
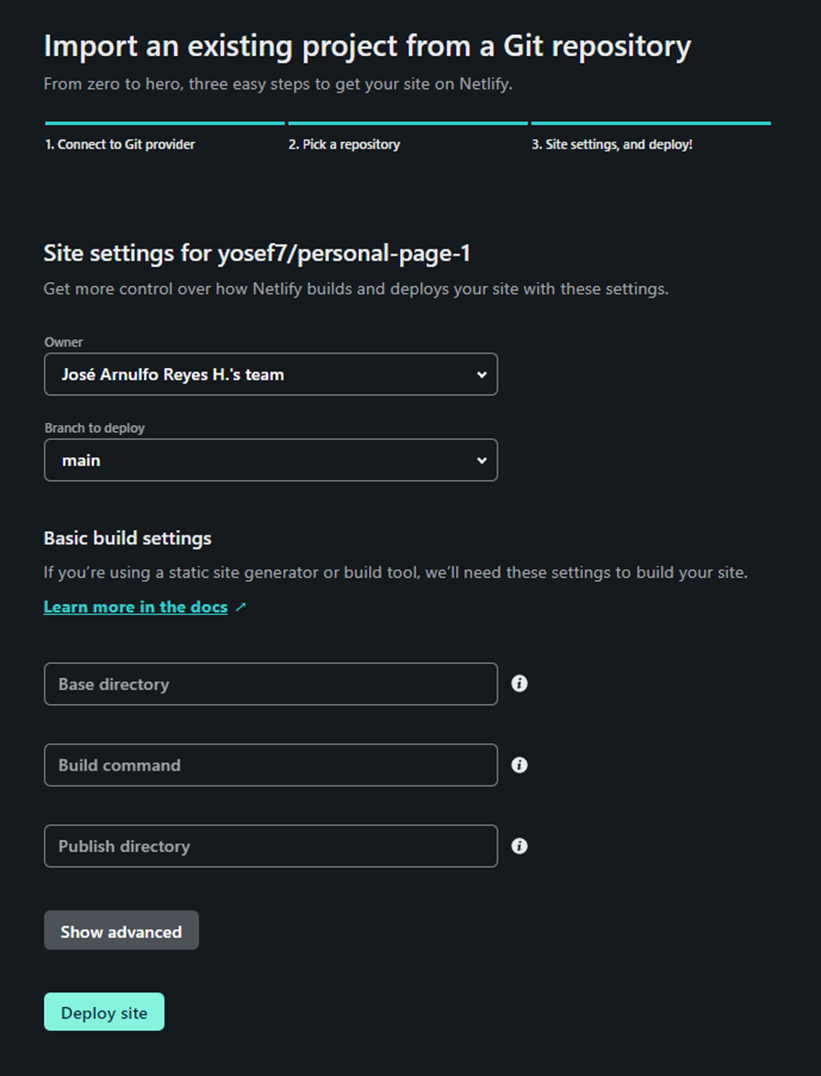
Configurar los ajustes. Dado que su sitio web es simplemente estático, no hay mucho que hacer aquí. Simplemente haga clic en Implementar sitio (Deploy site) para continuar.
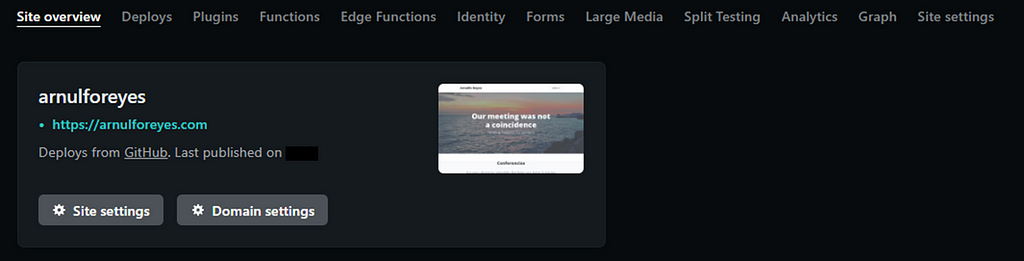
¡Tu sitio web ya está listo para publicarse! ¡Ya has terminado! Su nuevo sitio web está publicado y puede verlo haciendo clic en el enlace verde.
Planeo escribir otro artículo, mostrare como conectar un dominio de Namecheap a una web implementada con Netlify. Estén atentos.
¡Gracias por llegar hasta acá!
Si gustas puedes seguirme en mis redes sociales en Instagram @arnulfo
“Muéstrame el incentivo y te mostraré el resultado”. — Charlie Munger
Los incentivos bien diseñados tienen el poder de crear grandes resultados; los incentivos mal diseñados tienen el poder de… bueno… crear resultados terribles.
Para leer y seguir investigando:
En pocas palabras, si una medida de rendimiento se convierte en un objetivo declarado, los humanos tienden a optimizarla, independientemente de las consecuencias asociadas. La medida a menudo pierde su valor como medida.

Una vez que internalizas este marco, lo ves a tu alrededor:
Planeo escribir más sobre el tema de los incentivos en el futuro. Estén atentos.
¡Gracias por llegar hasta acá!
Si gustas puedes seguirme en mis redes sociales en Instagram @arnulfo
Para obtener mejores resultados, necesita importantes ventajas competitivas.
Pero al contrario de lo que le han dicho, la mayoría de ellos no requieren talento.

Ventajas competitivas que no requieren talento.
¿Cuáles son algunos otros que agregaría a la lista?
Sígueme para conocer más temas sobre la vida, los negocios, los modelos mentales y las finanzas.
No permitas que tu equipo sufra agotamiento relacionado con el trabajo. Considera estos consejos para mantener un ambiente de trabajo positivo y colaboradores productivos.
Durante los cierres por pandemia se normalizo la disponibilidad de los colaboradores las 24 horas, los 7 días de la semana, muchos de nosotros nos encontrábamos cerca de nuestras computadoras portátiles en todo momento. Este nuevo habito llevó a muchas personas a experimentar agotamiento, con el estrés y la frustración afectando negativamente la calidad de su trabajo, sus relaciones personales e incluso su salud mental.

La falta de compromiso es uno de los principales asesinos del rendimiento. Al conectar los objetivos estratégicos con las actividades diarias, le muestra a cada colaborador que su arduo trabajo marca la diferencia en el éxito de la empresa. Esto a la vez aumenta su sentido de éxito.
La falta de conexión personal con un líder puede hacer que los miembros del equipo se aíslen y se guarden los problemas, no hay nada como el aislamiento y el silencio para hacer que los pequeños problemas se conviertan en problemas más grandes.
Para asegurarse de que estas fallas en la comunicación no descarrilen su misión, deje que su equipo vea que usted es humano. Comparta sus logros y desafíos. Hacer esto ayudó a desarrollar conexiones y un sentido de camaradería que facilita el intercambio de problemas para el equipo.
Descubrí que establecer un horario para compartir información personal durante las reuniones semanales del equipo puede generar resultados positivos.
Las reuniones de equipo suelen ser el lugar donde se abordan problemas y en ocasiones muchos de estos problemas no se resuelve tan rápido. Esto puede resultar abrumador, erosionar la confianza y provocar agotamiento. El intercambio personal puede contribuir en gran medida a ayudar a los miembros del equipo a sentirse lo suficientemente inspirados y seguros como para compartir sus ideas menos convencionales.
Pregunte rutinariamente a los miembros del equipo: ¿Cómo están? y ¿Cómo se sienten?, y asegúrese de mantener conversaciones individuales regulares. Para mantener un compromiso alto, brinde a su equipo objetivos estratégicos y ayude a alcanzarlos.
Si nota un largo silencio en una llamada, intente descubrir lo que no se dice. Muestre a su equipo que tiene la paciencia para escuchar, incluso cuando parece incómodo. Esta es una de las mejores maneras de volver a involucrar a los miembros del equipo que pueden estar teniendo dificultades.
Trabaje en grupos pequeños cuando sea posible. Esto lo ayudará a comprender si sus plazos son realistas para que pueda evitar poner estrés adicional en su equipo.
La visión a largo plazo es esencial para cualquier organización, pero las metas a corto plazo ayudan a garantizar que el progreso sea constante y manejable.

Agile ayuda a contrarrestar el agotamiento de los colaboradores, que con demasiada frecuencia trabajan en entornos de aislamiento y progreso lento. Lo primero que le enseña la metodología ágil es mantener sus plazos y el alcance de su trabajo adecuados a incrementos de dos semanas. Además, cada miembro del equipo tiene la oportunidad de expresar lo que salió mal, lo que salió bien y las formas de mejorar. Esto hace que cada paso sea manejable y brinda a los proyectos un nivel de claridad que alivia el estrés y la confusión que a menudo conducen al agotamiento.
Eliminar el agotamiento por completo nunca será posible, pero hay pasos que puede seguir para asegurarse de que tu equipo se sienta apoyado y escuchado. Es posible que no vea resultados positivos de la noche a la mañana; facilitar procesos de trabajo más compasivos y ágiles llevará tiempo. Pero al hacer estos cambios ahora, puede estar seguro de que todos los miembros de su organización se beneficiarán.
Gracias por llegar hasta aquí.
Recibo con mucho agrado los comentarios y las críticas constructivas.
Si gustas puedes seguirme en mis redes sociales @arnulfo
Por: Tyler Perry
Tengo esta analogía del árbol cuando pienso en las personas en mi vida, ya sean amigos, familiares, conocidos, empleados, compañeros de trabajo, quien sea. Todos están colocados dentro de lo que llamo mi árbol, es así:

PERSONAS HOJA
Algunas personas llegan a tu vida y son como las hojas de un árbol. Solo están allí por una temporada. No puedes depender de ellos o contar con ellos porque son débiles y solo están ahí para darte sombra. Como las hojas, están ahí para tomar lo que necesitan y tan pronto como hace frío o sopla un viento en tu vida, se van. No puedes estar enojado con ellos, es solo lo que son.
PERSONAS DE RAMA
Hay algunas personas que llegan a tu vida y son como las ramas de un árbol. Son más fuertes que las hojas, pero hay que tener cuidado con ellas. Se quedarán durante la mayoría de las estaciones, pero si pasas por una tormenta o dos en tu vida, es posible que los pierdas.
La mayoría de las veces se separan cuando es difícil. Aunque son más fuertes que las hojas, debes probarlas antes de salir corriendo y poner todo tu peso sobre ellas. En la mayoría de los casos, no pueden soportar demasiado peso. Pero, de nuevo no puedes enojarte con ellos, es solo lo que son.
PERSONAS DE RAÍZ
Si puedes encontrar algunas personas en tu vida que son como las raíces de un árbol, entonces has encontrado algo especial. Como las raíces de un árbol, son difíciles de encontrar porque no están tratando de ser vistos. Su único trabajo es sostenerte y ayudarte a vivir una vida fuerte y saludable. Si prosperas, ellos son felices. Se mantienen discretos y no dejan que el mundo sepa que están allí. Y si pasas por una tormenta terrible, te sostendrán. Su trabajo es sostenerte, pase lo que pase, y nutrirte, alimentarte y regarte.
Así como un árbol tiene muchas ramas y muchas hojas, pero pocas raíces, también lo son los seres humanos. Mira tu propia vida. ¿Cuántas hojas, ramas y raíces tienes? ¿Qué eres en la vida de los demás?
¡GRACIAS A DIOS POR LAS RAÍCES Y TRATA DE SER RAÍZ PARA MUCHOS!
Gracias por llegar hasta aquí.
Recibo con mucho agrado los comentarios y las críticas constructivas.
Si gustas puedes seguirme en mis redes sociales en Instagram @arnulfo
Vamos a detallar…
A menudo me han preguntado por qué me importa tanto ayudar a la gente a aprender a codificar. Siempre he respondido diciendo que el código es poder, y aprender a codificar te da mucho poder. Cuanto más comprenda el código, más comprenderá el impacto que tienen las plataformas y los productos tecnológicos en la vida de las personas, ya sea a través de la implementación de funciones específicas o la falta de implementación de ciertas funciones.

Importa poco si estos impactos son intencionales o no. Por ejemplo, cuando ha creado una plataforma que una parte importante de la sociedad utiliza para la comunicación. Tu código tiene un impacto directo en la sociedad.
Cuando escribe un código que ayuda a determinar quién obtiene un préstamo, influye en quién puede permitirse comprar una casa.
Está muy claro que en Panamá, Brasil, Estados Unidos, Japón y en muchos lugares del mundo, que aquellos que tienen el poder están desesperados por mantener ese poder y están dispuestos a usar la fuerza — “cualquier medio necesario” es una frase demasiado común — para aferrarse a ese poder. Y esa fuerza se usa de manera desproporcionada, en un grado alucinante, contra los negros, los indígenas y cualquier persona que pueda clasificarse como minoría.
A medida que aprendas a codificar, tenga en cuenta el poder que está ganando.
Mientras trabaja en proyectos, ya sean sus propios proyectos o aquellos que están controlados por otra persona, concéntrese en proyectos que comparten el poder. Por favor, niéguese a trabajar en proyectos que consoliden el poder, especialmente para aquellos que lo usarán contra otros.
Thanks for reading!
¡Gracias por leer!
Gracias por llegar hasta aquí. Recibo con mucho agrado tus comentarios. Si gustas puedes seguirme en mis redes sociales @arnulfo_07 o LinkedIn.
Comparto con ustedes la actualización del Logo de la comunidad panameña del lenguaje de programación Python.
Árbol de Guayacán, Mariposas, Canal de Panamá, Sol Brillante, Águila Harpía, Cielo y Mar Azul.
Síguenos en tu red social favorita: @PythonPanama
Python Panamá en Meetup https://meetu.ps/c/4nSg4/vmjqQ/a
Idea: Kiria Berdiales y Arnulfo Reyes
Diseñadora Gráfica: Graciela Sánchez

En términos muy generales, los datos pueden clasificarse como continuos o categóricos.
Las categóricas son muy útiles para conocer información de tipo cualitativo, es decir, alguna cualidad de los datos. Las continuas nos aportan datos cuantitativos, es decir, cantidades y valores representados por números.
Pandas no clasifica ampliamente los datos como continuos o categóricos. En cambio, tiene definiciones técnicas precisas para muchos tipos de datos distintos.

La siguiente tabla contiene todos los tipos de datos de pandas, con sus cadenas equivalentes y algunas notas sobre cada tipo:

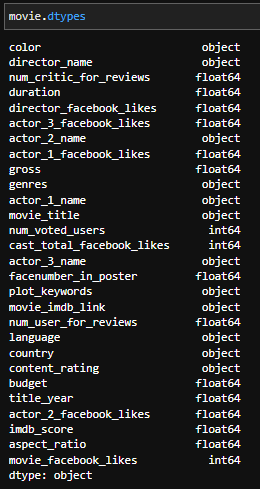
Mostremos el tipo de datos de cada columna en un DataFrame.
Utilicemos el atributo dtypes para mostrar cada columna junto con su tipo de datos:
Utilice el método dtypes.value_counts() para devolver el recuento de cada tipo de datos.
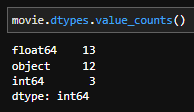
Cada columna debe ser de un tipo, por ejemplo cada valor en la columna aspect_ratio es un flotante de 64 bits y cada valor de la columna movie_facebook_likes es un número entero de 64 bits.
Datos homogéneos es otro término para referirse a columnas que tienen todas el mismo tipo.
Cuando una columna, es del tipo de datos de objeto, indica que toda la columna son cadenas.
Pandas creó su propio tipo de datos categóricos para manejar columnas de cadenas (o números) con un número fijo de valores posibles.
Essential basic functionality - pandas 1.4.1 documentation
Thanks for reading!
¡Gracias por leer!
Gracias por llegar hasta aquí. Recibo con mucho agrado tus comentarios. Si gustas puedes seguirme en mis redes sociales en Instagram @arnulfo o LinkedIn.
En ocasiones te gustará realizar operaciones en los componentes individuales y no en todo el DataFrame.
Se puede acceder a cada uno de los tres (3) componentes de un DataFrame (índice, columnas y datos) directamente desde un DataFrame. Cada uno de esos componentes es en sí mismo un objeto de Python con sus atributos y métodos únicos.

Vamos a extraer el índice, las columnas y los datos del DataFrame en variables separadas y luego mostraremos las columnas y el índice y como se heredan del mismo objeto.
Utilizaremos el DataFrame
movie = pd.read_csv('data/movie.csv')
index = movie.index
columns = movie.columns
data = movie.valuesMostrar los valores de cada componente:
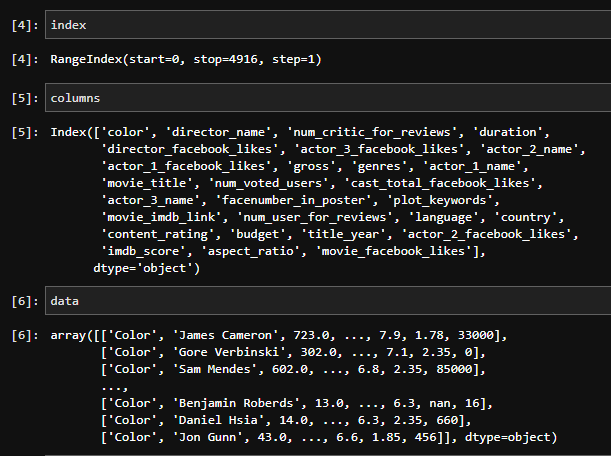
Mostrar el tipo (type) de cada componente del DataFrame (DF)
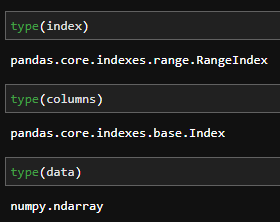
Los tipos para el índice como para las columnas están relacionados. El método integrado issubclass comprueba si RangeIndex es realmente una subclase de Index
issubclass(pd.RangeIndex, pd.Index)
True
Una forma común de referirse a los objetos es incluir el nombre del paquete seguido del nombre del tipo de objeto.
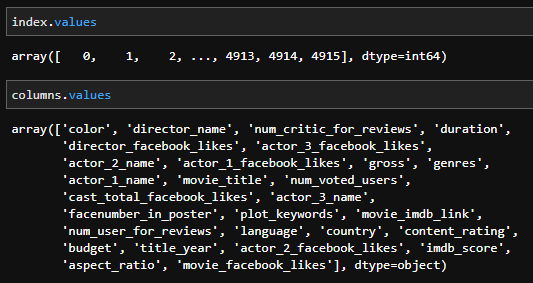
Observe cómo el atributo values DataFrame devolvió una matriz NumPy n-dimensional o ndarray. La mayoría de los pandas dependen en gran medida del ndarray.
Podrían considerarse el objeto base para los pandas sobre el que se construyen muchos otros objetos. Para ver esto, podemos mirar los valores del índice y
columnas:
Indexing and selecting data - pandas 1.4.3 documentation
Thanks for reading!
¡Gracias por leer!
Gracias por llegar hasta aquí. Recibo con mucho agrado tus comentarios. Si gustas puedes seguirme en mis redes sociales en Instagram @arnulfo o LinkedIn.