
Ocurrió fuera del ambiente del colegio y los únicos dos consejos que me dieron, que yo recuerde:

Para ser sincero no utilice esos consejos por mucho tiempo, me sentía más tranquilo mirando el rostro de las personas ya que de esa manera sentía que podía transmitir mejor mis ideas.
¿Evitar estar nervioso (manos temblorosas) por hablar al frente de personas?, ¡uhm! la realidad es que uno siempre esta nervioso, no importa cuando leas esto.
Aquí debo ser agradecido, por lo siguiente:
Agradecer que desde que yo era muy pequeño aprendí a comunicarme con mi abuelo. Cuando el era apenas un bebe sufrió una enfermedad que en ese entonces casi le quita la vida pero pudo escapar de la muerte aunque le dejo una secuela, lo dejo sordo. En su hogar no tenían la facilidades, ni tampoco en esos tiempos se enseñaba el lenguaje de señas como se hace actualmente. Así que les toco improvisar sus propios lenguajes de señas y a nosotros nos toco aprenderlo. Eso en cierta manera hizo que mi mamá y yo fortaleciéramos el tema de expresarnos.
Me gusta mucho esta frase: existen más conexiones entre el cerebro y las manos que con otras partes del cuerpo. Esto lo escribieron Allan y Barbara Pease, en su libro: El Lenguaje del Cuerpo — Cómo interpretar a los demás a través de sus gestos.
Me siento muy identificado por las pláticas que tenia con mi abuelo y lo mucho que trasmitíamos en nuestras conversaciones sin utilizar palabras. Puedo decir que las conversaciones junto a el me han ayudado a transmitir lo que quiero expresar.
Pero tu viniste por los consejos para hablar en publico así que vamos de una vez por ellos luego de esta pequeña anécdota.
Son alrededor de 10 años dando conferencias, experiencia de vida y diversas pláticas en donde he tenido la oportunidad de estar en frente de grupos pequeños, cientos de personas y a veces de miles. Creo que puedo resumirte algunos consejos que añadirán valor pero tengo que ser sincero contigo no es algo que aprenderás de la noche a la mañana y tal vez algunos consejos ya los hayas escuchado así que te invito a que me acompañes a reforzar estos puntos.

Gran parte de lo que se comparte en público sucede mucho antes de que subas al escenario. La preparación y la práctica son claves.
Me gustaría mucho que compartas tu opinión conmigo, si tienes alguna pregunta no dudes en hacerla o por el contrario necesitas algún consejo puedes escribirme: MD.
La ciencia de datos: “es la disciplina de hacer que la información sea útil”.

La cual esta relacionada a lo siguiente:
Se ha mencionado mucho sobre esto: “Un data scientist es un estadístico que puede programar”.
La historia de cómo los científicos de datos se volvieron atractivos es principalmente la historia de la unión de la disciplina madura de las estadísticas con una muy joven: la informática.
Lectura recomendada:
A Very Short History Of Data Science
Aunque Wikipedia tiene una muy buena definición.
La ciencia de datos es un ‘concepto para unificar estadística, análisis de datos, aprendizaje automático y sus métodos relacionados’ para ‘entender y analizar fenómenos reales’ con datos.
Es a través de nuestras acciones, nuestras decisiones, que afectamos el mundo que nos rodea.
¿Cuál es el significado de data science? was originally published in Linked - Ciencia de Datos on Medium, where people are continuing the conversation by highlighting and responding to this story.

Las personas que trabajan con datos deben ser críticos y estar muy atentos para ver cosas que otros pasan desapercibido.
Hay mucho miedo por los números. […] Quizás es porque de niños recibimos algún trauma inducido por las matemáticas de la escuela primaria.
Las estadísticas se han utilizado para mentir en anuncios, en lugares de trabajo y en muchos otros lugares. Creeme la gente hará cualquier cosa para obtener ventas o buenas calificaciones.
Desde hace varios meses esta idea a estado dándole vueltas a mi cabeza.
Para muestra un botón:
Colgate's '80% of dentists recommend' claim under fire | marketinglaw
Es bastante incómodo ver estas investigaciones y al poco tiempo darte cuenta que eran falsas.
A pesar que estas noticias ocurrieron hace algunos años, no dejan de ocurrir nuevas historias en nuestro día a día.
Me parece muy interesante el siguiente libro: Cómo mentir con estadísticas de Darrell Huff. Cuando observe la siguientes páginas 59–60–61, veo que estos ejemplos los podemos ver actualmente. Cuántos de nosotros no hemos estado en reuniones donde de manera muy sutil se juega con la visualización de los datos.
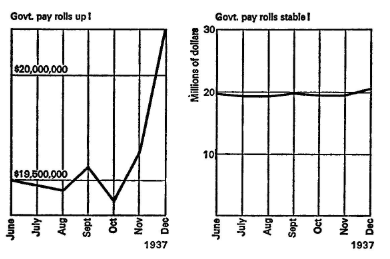
No debemos olvidar el objetivo principal de los dashboard o las visualizaciones
En la era del Big Data es muy importante tener en cuenta que entre más datos manejemos hay mayor posibilidad de errores.
Si eres responsable de publicar dashboard o debes interpretar datos, no dudes en tomar algún curso de estadística y más importante pedir consejo a algún profesional.
Gracias por leer mi publicación.
Recibo con mucho agrado los comentarios y las críticas constructivas.
Me pueden encontrar en IG @arnulfo.
¿Qué tan ciertas son las estadísticas? was originally published in Linked - Ciencia de Datos on Medium, where people are continuing the conversation by highlighting and responding to this story.
Organizes events and is speaker for FLOSS community in Panama and LATAM.
My nickname in the matrix [IRC] is: yosef7

2019
27, April || FLISoL 2019
28, May || Fedora 30 Release Party
2018
21, April || FLISoL 2018
29, May || Fedora Release Party
08–11, Aug || Flock 2018 || Dresden, Germany
22, Aug || Docker Meetup 05 by Fedora
01, Sep || Fedora Installation Day
2017
21, February || Python Meetup Vol. VI
22, April || FLISoL 2017
13, 14, 15, July || FAD — Cusco, Perú.
2016
Sat 23, April || FLISoL 2016 Panamá.
Sat 11, 25, June || Pre Linux Day.
Sat 02, July || ‘Fedora 24 Release Party’
Sat 09, 23 July || Pre Linux Day.
Sat 06, August || Linux Day.
13–15, October || FUDCon LATAM. FUDCon Puno, Perú.
22, October || Python Meetup
24, September || ‘Desconferencia’ — Symfony & Drupal
2015
Mon 03, August || Semana de Ingeniería.
Wed 05, August || Semana de Ingeniería
Sat 19, September || Software Freedom Day Panamá.
La ciencia de datos ha tenido uno de los crecimiento más rápidos en los últimos años, además proporciona un gran valor en todas las industrias y áreas de estudio.

Iniciar una empresa de tecnología, desarrollar un producto o ganar interacción con muchos seguidores se ha vuelto cada vez más fácil gracias a la disminución de costos de computación, almacenamiento en la nube, también gracias a la conectividad y accesibilidad que nos ofrecen distintas plataformas que nos permiten llegar a millones de usuarios mes a mes, el tiempo que tarda en llegar un producto ha disminuido drásticamente y sigue disminuyendo.
La combinación de los siguientes factores: incremento en el auge de fabricación de dispositivos + aumento de los dispositivos conectados a Internet + mayor tiempo que se pasa en línea, ha provocado un aumento en el volumen de datos.
Esto ha provocado un gran interés en extraer los datos y obtener información para ayudar a construir excelentes productos. La capacidad de una empresa para competir ahora se mide por la manera en que aplica con éxito los análisis de sus bases de datos todo esto para impulsar la innovación.
Los profesionales que trabajan con los datos tienen una gran demanda actualmente.

Cuatro resultados específicos en los cuales centrarse:
Estos cuatro resultados nos permiten identificar a dos tipos diferentes de científicos de datos: analistas de productos y desarrolladores de algoritmos.
¡Gracias por leer!
Si gustas puedes seguir las redes sociales de @PythonPanama en IG, LinkedIn y Twitter.
La importancia de la Ciencia de Datos was originally published in Linked - Ciencia de Datos on Medium, where people are continuing the conversation by highlighting and responding to this story.
Una guía que puede ayudar a alguien o a mi mismo si olvidó hacer esta configuración.
Recomiendo seguir el blog de: Laura Roger. Ella explicó el uso de Flow en este video (al final del video), lo que he hecho es investigar la solución y resumir algunos puntos. Espero les funcione.
Lo primero es hacer una lista en Sharepoint (SP). He creado una lista bastante sencilla para realizar este ejemplo:
Ahora utilizaremos Flow. Breve explicación de que es Flow.
Flow nos permite obtener el archivo adjunto del elemento creado en Sharepoint (SP), al crear una matriz almacenamos el archivo adjunto, finalmente utilizaremos esta “matriz de archivo adjunto” y lo enviamos por correo electrónico.
Comencemos:
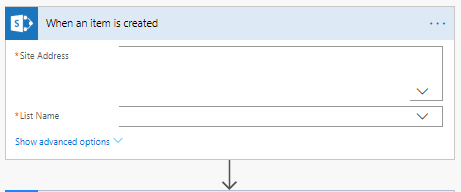
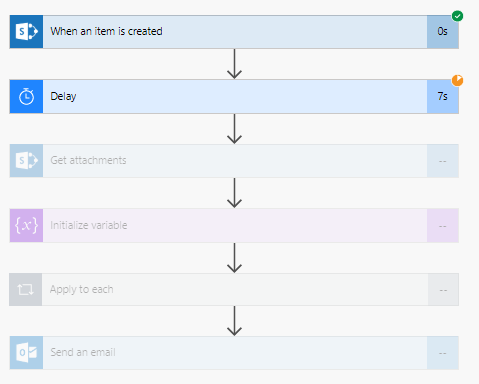
2. Añadir el siguiente paso “Delay”: permite tener un tiempo a favor para obtener el archivo adjunto sin error.
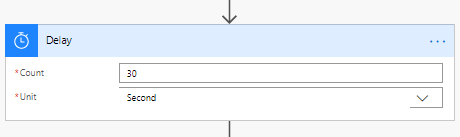
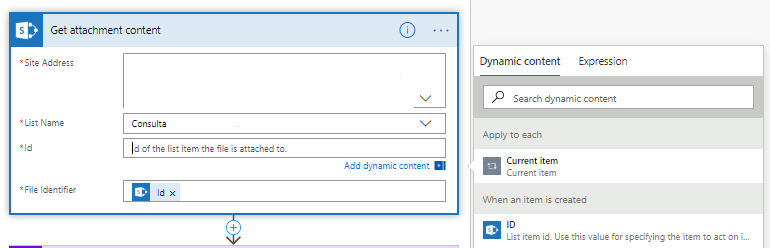
3. Añadir un nuevo paso “Get attachments”: En este paso se obtendrá el archivo adjunto del elemento creado. El nombre del sitio y el nombre de la lista siguen siendo los mismos del paso anterior. El “Id” nos permite identificar el archivo adjunto del elemento creado. ID.
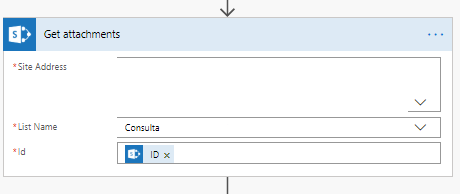
4. Añadir un nuevo paso Variable — “Initialize variable”: El paso anterior nos permite tener control de los archivos adjuntos. Ahora con esta variable nos permite almacenar los archivos en una sola matriz. TK
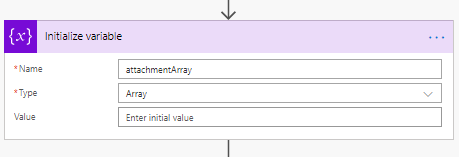
5. Añadir un nuevo paso “Apply to each”: Este paso nos ayuda a buscar y almacenar el contenido del archivo adjunto en la matriz. El nombre del sitio y el nombre de la lista siguen siendo los mismos del paso anterior.

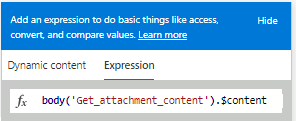
Luego haga clic en “Agregar una acción” y seleccione: Variable — Añadir a la variable matriz.
{
"Name":,
"ContentBytes":
}
6. Añadir un nuevo paso: “Send an email”
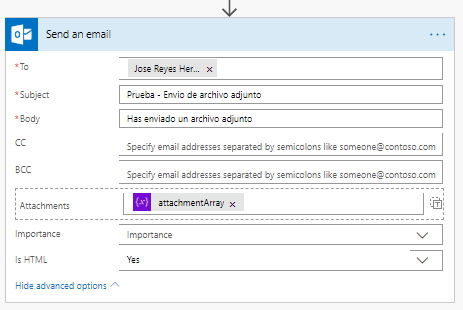
Y realizamos la configuración del envío del correo:
Guarde su flujo, luego vaya a su lista y cree un nuevo elemento de la lista con los archivos adjuntos para probar. Recuerda ser paciente si pones el paso de “Delay”.
Debería recibir un correo electrónico con los archivos adjuntos que agregó al elemento de la lista.
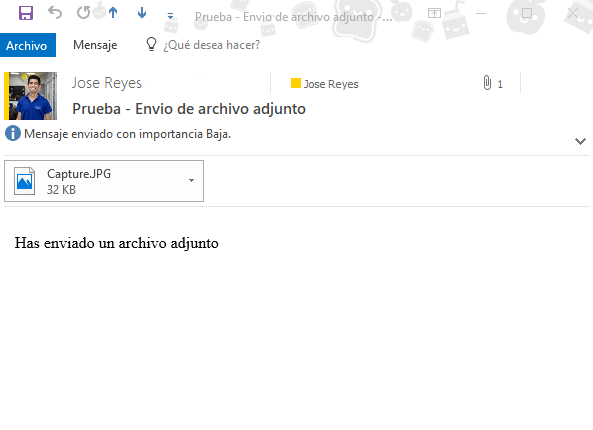
Esto resuelve muchos de los problemas que tenía y espero que te ayuden de alguna manera.
Me gustaría mucho que compartas tu opinión conmigo, si tienes alguna pregunta no dudes en hacerla, por el contrario si necesitas algún consejo puedes escribirme: MD.

Más allá de las famosas 7V del Big Data, existe una pieza clave en la formación de una cultura empresarial basada en los datos, esta clave radica en las personas.
Para implementar con éxito esta cultura se necesita un cambio de paradigma, un cambio cultural que se adopte de forma global en el lugar donde trabajas y a la vez demostrar los beneficios efectivos que aportan los datos a toda la organización.
He aprendido que para lograr el éxito en los objetivos que te propongas debes tener mucho orden. La secuencia de prioridades seria algo asi: personas, datos y tecnología.
El estudio realizado por McKinsey Global Institute del año 2014 revela información valiosa que debemos tomar en cuenta de nuestros clientes para mejorar las ganancias y crecimiento positivo.
Intensive users of customer analytics are 23 times more likely to clearly outperform their competitors in terms of new- customer acquisition than non-intensive users, and nine times more likely to surpass them in customer loyalty. Our survey results also show that the likelihood of achieving above-average profitability is almost 19 times higher for customer-analytics champions as for laggards. Even more impressive is their likelihood of migrating an above-average share of customers to profitable segments, at 21 times that of non-intensive users of customer analytics
Una empresa puede utilizar los datos para ser impulsada de esa manera reducir la incertidumbre y generar mejores decisiones, es decir, los datos son utilizados para tomar mejores decisiones y lograr los objetivos de la empresa.
Como lo mencione en una de mis publicaciones: tomar decisiones basadas en los datos nos hace tener una especie de superpoder. Nos brinda respuestas objetivas que pueden poner fin a argumentos. Creando así una fuente de verdad y disminuyendo las discusiones.
Para lograr la toma de decisiones basada en datos usted necesita:
Pero sin lugar a dudas, el compromiso de su equipo de trabajo es crucial para lograr los objetivos en la empresa. Mucho más cuando esa misión implica cambios de comportamiento y nuevas prácticas.
Realizar este cambio ocurre de distinta manera en cada organización, pero usted puede iniciar con pequeños pasos para luego hacer pasos agigantados.
¿Cómo lo puedes lograr?
Lograr que los datos sean su ventaja competitiva es lo que hará crecer o desaparecer a las empresas en el futuro.
Me gustaría mucho que compartas tu opinión conmigo, si tienes alguna pregunta no dudes en hacerla, por el contrario si necesitas algún consejo puedes escribirme: MD.
Con mucho gusto te respondere y gracias por llegar hasta aquí.